
《程序员的自我修养--链接装载与库》学习笔记 Part 4 库与运行库
[TOC]
本文为《程序员的自我修养–链接装载与库》学习笔记 Part 4 库与运行库.
第10章 内存
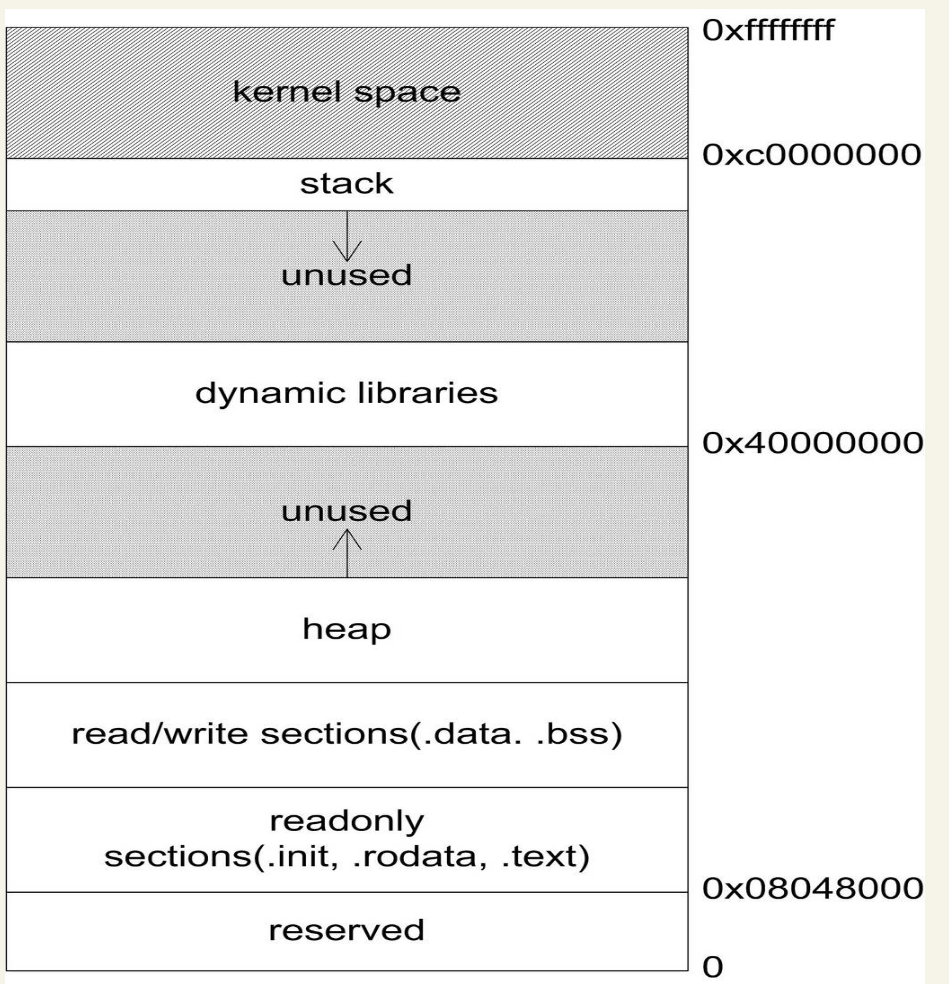
10.1 程序的内存布局
平坦(flat)的内存模型
布局
内核空间
用户空间
栈: 栈用于维护函数调用的上下文, 离开了栈函数调用就没法实现. 栈通常在用户空间的最高地址处分配, 通常有数兆字节的大小.
堆: 堆是用来容纳应用程序动态分配的内存区域, 当程序使用
malloc或new分配内存时, 得到的内存来自堆里. 堆通常存在于栈的下方 (低地址方向) , 在某些时候, 堆也可能没有固定统一的存储区域. 堆一般比栈大很多, 可以有几十至数百兆字节的容量.可执行文件映像: 这里存储着可执行文件在内存里的映像, 在第6章已经提到过, 由装载器在装载时将可执行文件的内存读取或映射到这里.
保留区: 保留区并不是一个单一的内存区域, 而是对内存中受到保护而禁止访问的内存区域的总称, 例如, 大多数操作系统里, 极小的地址通常都是不允许访问的, 如
NULL.动态链接库映射区: 在 Linux 下, 如果可执行文件依赖其他共享库, 那么系统就会为它在从
0x40000000开始的地址分配相应的空间, 并将共享库载入到该空间.Linux
- 栈向低地址增长, 堆向高地址增长. 当栈或堆现有的大小不够用时, 它将按照图中的增长方向扩大自身的尺寸, 直到预留的空间被用完为止.
段错误(segment fault)或者 “非法操作, 该内存地址不能read/write” 的错误信息的原因:
- 非法指针解引用造成的错误.
- 当指针指向一个不允许读或写的内存地址, 而程序却试图利用指针来读或写该地址的时候, 就会出现这个错误.
10.2 栈与调用惯例
10.2.1 什么是栈
esp寄存器标明了栈顶, 地址为0xbffffff4. 在栈上压入数据会导致esp减小, 弹出数据使得esp增大.栈保存了一个函数调用所需要的维护信息, 这常常被称为堆栈帧 (Stack Frame) 或活动记录 (Activate Record).

ebp寄存器指向了函数活动记录的一个固定位置,ebp寄存器又被称为帧指针 (Frame Pointer) .栈帧一般包括如下几方面内容:
- 函数的返回地址和参数.
- 临时变量: 包括函数的非静态局部变量以及编译器自动生成的其他临时变量.
- 保存的上下文: 包括在函数调用前后需要保持不变的寄存器.
一个 i386 下的函数总是这样调用的:
- 把所有或一部分参数压入栈中, 如果有其他参数没有入栈, 那么使用某些特定的寄存器传递.
- 把所有或一部分参数压入栈中, 如果有其他参数没有入栈, 那么使用某些特定的寄存器传递.
- 把当前指令的下一条指令的地址压入栈中.
- 跳转到函数体执行.
i386 函数体的 “标准” 开头是这样的 (但也可以不一样) :
push ebp: 把ebp压入栈中 (称为 old ebp) .mov ebp, esp: ebp = esp(这时ebp指向栈顶, 而此时栈顶就是 old ebp) .- [可选]
sub esp, XXX: 在栈上分配XXX字节的临时空间. - [可选]
push XXX: 如有必要, 保存名为XXX寄存器 (可重复多个) . - [可选]
pop XXX: 如有必要, 恢复保存过的寄存器 (可重复多个) . mov esp, ebp: 恢复ESP同时回收局部变量空间.pop ebp: 从栈中恢复保存的ebp的值.ret: 从栈中取得返回地址, 并跳转到该位置.
例子
- 函数代码
1
2
3
4int foo()
{
return 123;
}foo函数汇编代码分析
第 4 步的代码用于调试. 这段汇编大致等价于如下伪代码:
1
2
3
4
5edi = ebp – 0x0C;
ecx = 0x30;
eax = 0xCCCCCCCC;
for (; ecx != 0; --ecx, edi+=4)
*((int*)edi) = eax;- 之所以会出现 “烫” 这么一个奇怪的字, 就是因为 Debug 模式在第 4 步里, 将所有的分配出来的栈空间的每一个字节都初始化为
0xCC. 0xCCCC(即两个连续排列的0xCC) 的汉字编码就是烫, 所以0xCCCC如果被当作文本就是 “烫” . - 将未初始化数据设置为
0xCC的理由是这样可以有助于判断一个变量是否没有初始化. 如果一个指针变量的值是0xCCCCCCCC, 那么我们就可以基本相信这个指针没有经过初始化. - 然这个信息仅供参考, 编译器检查未初始化变量的方法并不能以此为证据. 有时编译器还会使用
0xCDCDCDCD作为未初始化标记, 此时我们就会看到汉字 “屯屯” .
- 之所以会出现 “烫” 这么一个奇怪的字, 就是因为 Debug 模式在第 4 步里, 将所有的分配出来的栈空间的每一个字节都初始化为
不过在有些场合下, 编译器生成函数的进入和退出指令序列时并不按照标准的方式进行. 例如一个满足如下要求的 C 函数:
- 函数被声明为 static (不可在此编译单元之外访问) .
- 函数在本编译单元仅被直接调用, 没有显示或隐式取地址 (即没有任何函数指针指向过这个函数) .
- 编译器可以确信满足这两条的函数不会在其他编译单元内被调用, 因此可以随意地修改这个函数的各个方面–包括进入和退出指令序列–来达到优化的目的.

10.2.2 调用惯例
函数的调用方和被调用方对于函数如何调用须要有一个明确的约定, 只有双方都遵守同样的约定, 函数才能被正确地调用, 这样的约定就称为调用惯例 (Calling Convention) .
调用惯例一般会规定如下几个方面的内容.
函数参数的传递顺序和方式
- 调用惯例要规定函数调用方将参数压栈的顺序: 是从左至右, 还是从右至左. 有些调用惯例还允许使用寄存器传递参数, 以提高性能.
栈的维护方式
- 弹出的工作可以由函数的调用方来完成, 也可以由函数本身来完成.
名字修饰 (Name-mangling) 的策略
- 调用管理要对函数本身的名字进行修饰. 不同的调用惯例有不同的名字修饰策略.
在 C 语言里, 存在着多个调用惯例, 而默认的调用惯例是 cdecl.
对于函数
foo的声明, 它的完整形式是:1
int _cdecl foo(int n, float m)

例子
- 函数代码
1
2
3
4
5int foo(int n, float m)
{
int a = 0, b = 0;
...
}foo函数栈布局调用代码
1
2
3
4
5
6
7
8
9
10
11void f(int x, int y)
{
...
return;
}
int main()
{
f(1, 3);
return 0;
}main 函数的执行流程
几项主要的调用惯例

不少编译器还提供一种称为 naked call 的调用惯例, 这种调用惯例用在特殊的场合, 其特点是编译器不产生任何保护寄存器的代码, 故称为 naked call.
C++ 自己还有一种特殊的调用惯例, 称为 thiscall, 专用于类成员函数的调用. 其特点随编译器不同而不同.
- 在 VC 里是 this 指针存放于
ecx寄存器, 参数从右到左压栈. - 对于 gcc, thiscall 和 cdecl 完全一样, 只是将 this 看作是函数的第一个参数.
- 在 VC 里是 this 指针存放于


10.2.3 函数返回值传递
除了参数的传递之外, 函数与调用方的交互还有一个渠道就是返回值.
eax是传递返回值的通道. 函数将返回值存储在eax中, 返回后函数的调用方再读取eax.对于返回 5~8 字节对象的情况, 几乎所有的调用惯例都是采用
eax和edx联合返回的方式进行的. 其中eax存储返回值要低 4 字节, 而edx存储返回值要高 1~4 字节.对于超过 8 字节的返回类型
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct big_thing
{
char buf[128];
}big_thing;
big_thing return_test()
{
big_thing b;
b.buf[0] = 0;
return b;
}
int main()
{
big_thing n = return_test();
}反汇编 (MSVC9) 一下 main 函数
1
2
3
4
5
6
7
8
9big_thing n = return_test();
00411498 lea eax,[ebp-1D0h]
0041149E push eax
0041149F call _return_test
004114A4 add esp,4
004114A7 mov ecx,20h
004114AC mov esi,eax
004114AE lea edi,[ebp-88h]
004114B4 rep movs dword ptr es:[edi],dword ptr [esi]return_test的原型实际是:big_thing return_test(void* addr);.-
rep movs a, b的意思就是将b指向位置上的若干个双字 (4 字节) 拷贝到由a指向的位置上, 拷贝双字的个数由ecx指定, 实际上这句复合指令的含义相当于memcpy (a, b, ecx * 4).
return_test的实现1
2
3
4
5
6
7
8
9
10
11
12
13big_thing return_test()
{
...
big_thing b;
b.buf[0] = 0;
004113C8 mov byte ptr [ebp-88h],0
return b;
004113CF mov ecx,20h
004113D4 lea esi,[ebp-88h]
004113DA mov edi,dword ptr [ebp+8]
004113DD rep movs dword ptr es:[edi],dword ptr [esi]
004113DF mov eax,dword ptr [ebp+8]
}ebp-88h存储的是return_test的局部变量b.中间 4 条指令可以翻译成如下的代码:
memcpy([ebp+8], &b, 128);.[ebp+8]指的是*(void**)(ebp+8), 即将地址ebp+8上存储的值作为地址, 由于ebp实际指向栈上保存的旧的ebp, 因此ebp+4指向压入栈中的返回地址,ebp+8则指向函数的参数. 而我们知道,return_test是没有真正的参数的, 只有一个 “伪参数” 由函数的调用方悄悄地传入, 那就是ebp-1D0h(这里的ebp是return_test调用前的ebp) 这个值. 换句话说 ,[ebp+8]=old_ebp-1D0h.
main 函数一开始初始化的汇编代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int main()
{
00411470 push ebp
00411471 mov ebp, esp
00411473 sub esp,1D4h
00411479 push ebx
0041147A push esi
0041147B push edi
0041147C lea edi,[ebp-1D4h]
00411482 mov ecx,75h
00411487 mov eax,0CCCCCCCCh
0041148C rep stos dword ptr es:[edi]
0041148E mov eax,dword ptr [___security_cookie (417000h)]
00411493 xor eax,ebp
00411495 mov dword ptr [ebp-4],eax- main 函数在保存了
ebp之后, 就直接将栈增大了1D4h个字节, 因此ebp-1D0h就正好落在这个扩大区域的末尾, 而区间[ebp-1D0h, ebp-1D0h + 128)也正好处于这个扩大区域的内部.
- main 函数在保存了
整个思路
首先 main 函数在栈上额外开辟了一片空间, 并将这块空间的一部分作为传递返回值的临时对象, 这里称为
temp.将
temp对象的地址作为隐藏参数传递给return_test函数.return_test函数将数据拷贝给temp对象, 并将temp对象的地址用eax传出.return_test返回之后, main 函数将eax指向的temp对象的内容拷贝给n.流程图
伪代码表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void return_test(void *temp)
{
big_thing b;
b.buf[0] = 0;
memcpy(temp, &b, sizeof(big_thing));
eax = temp;
}
int main()
{
big_thing temp;
big_thing n;
return_test(&temp);
memcpy(&n, eax, sizeof(big_thing));
}
如果返回值类型的尺寸太大, C 语言在函数返回时会使用一个临时的栈上内存区域作为中转, 结果返回值对象会被拷贝两次.
最后来看看如果函数返回一个 C++ 对象会如何:
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
using namespace std;
struct cpp_obj
{
cpp_obj()
{
cout << "ctor\n";
}
cpp_obj(const cpp_obj& c)
{
cout << "copy ctor\n";
}
cpp_obj& operator=(const cpp_obj& rhs)
{
cout << "operator=\n";
return *this;
}
~cpp_obj()
{
cout << "dtor\n";
}
};
cpp_obj return_test()
{
cpp_obj b;
cout << "before return\n";
return b;
}
int main()
{
cpp_obj n;
n = return_test();
}在没有开启任何优化的情况下, 直接运行一下, 可以发现程序输出为:
1
2
3
4
5
6
7
8ctor
ctor
before return
copy ctor
dtor
operator=
dtor
dtor反汇编 main 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16n = return_test();
00411C2C lea eax,[ebp-0DDh]
00411C32 push eax
00411C33 call return_test (4111F4h)
00411C38 add esp,4
00411C3B mov dword ptr [ebp-0E8h],eax
00411C41 mov ecx,dword ptr [ebp-0E8h]
00411C47 mov dword ptr [ebp-0ECh],ecx
00411C4D mov byte ptr [ebp-4],1
00411C51 mov edx,dword ptr [ebp-0ECh]
00411C57 push edx
00411C58 lea ecx,[ebp-11h]
00411C5B call cpp_obj::operator= (41125Dh)
00411C60 mov byte ptr [ebp-4],0
00411C64 lea ecx,[ebp-0DDh]
00411C6A call cpp_obj::~cpp_obj (41119Ah)

10.3 堆与内存管理
10.3.1 什么是堆
那么
malloc到底是怎么实现的呢?有一种做法是, 把进程的内存管理交给操作系统内核去做.
- 当然这是一种理论上可行的做法, 但实际上这样做的性能比较差, 因为每次程序申请或者释放堆空间都需要进行系统调用. 我们知道系统调用的性能开销是很大的, 当程序对堆的操作比较频繁时, 这样做的结果是会严重影响程序的性能的.
比较好的做法就是程序向操作系统申请一块适当大小的堆空间, 然后由程序自己管理这块空间, 而具体来讲, 管理着堆空间分配的往往是程序的运行库.
10.3.2 Linux 进程堆管理
进程的地址空间中, 除了可执行文件, 共享库和栈之外, 剩余的未分配的空间都可以被用来作为堆空间.
提供了两种堆空间分配的方式, 即两个系统调用.
brk()系统调用int brk(void* end_data_segment)brk()的作用实际上就是设置进程数据段的结束地址, 即它可以扩大或者缩小数据段 (Linux 下数据段和 BSS 合并在一起统称数据段) . 如果我们将数据段的结束地址向高地址移动, 那么扩大的那部分空间就可以被我们使用.
sbrk以一个增量 (Increment) 作为参数, 即需要增加 (负数为减少) 的空间大小, 返回值是增加 (或减少) 后数据段结束地址, 这个函数实际上是对brk系统调用的包装, 它是通过brk()实现的.
mmap()mmap()的作用就是向操作系统申请一段虚拟地址空间, 当然这块虚拟地址空间可以映射到某个文件 (这也是这个系统调用的最初的作用) , 当它不将地址空间映射到某个文件时, 我们又称这块空间为匿名 (Anonymous) 空间, 匿名空间就可以拿来作为堆空间.1
2
3
4
5
6
7void *mmap(
void *start,
size_t length,
int prot,
int flags,
int fd,
off_t offset);- 前两个参数分别用于指定需要申请的空间的起始地址和长度, 如果起始地址设置为 0, 那么 Linux 系统会自动挑选合适的起始地址.
prot/flags这两个参数用于设置申请的空间的权限 (可读, 可写, 可执行) 以及映射类型 (文件映射, 匿名空间等) .- 最后两个参数是用于文件映射时指定文件描述符和文件偏移的.
使用
mmap也可以轻而易举地实现malloc函数:1
2
3
4
5
6
7
8void *malloc(size_t nbytes)
{
void* ret = mmap(0, nbytes, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
if (ret == MAP_FAILED)
return 0;
return ret;
}glibc 的
malloc函数是这样处理用户的空间请求的:- 对于小于 128KB 的请求来说, 它会在现有的堆空间里面, 按照堆分配算法为它分配一块空间并返回.
- 对于大于 128KB 的请求来说, 它会使用
mmap()函数为它分配一块匿名空间, 然后在这个匿名空间中为用户分配空间.
可用堆空间上限取决于
- 不同的 Linux 内核版本.
- 系统的资源限制 (ulimit) , 物理内存和交换空间的总和等.
10.3.3 Windows 进程堆管理
- Windows 系统提供了一个 API 叫做
VirtualAlloc(), 用来向系统申请空间, 它与 Linux 下的mmap非常相似. 实际上VirtualAlloc()申请的空间不一定只用于堆, 它仅仅是向系统预留了一块虚拟地址, 应用程序可以按照需要随意使用. - 堆管理器 (Heap Manager) . 堆管理器提供了一套与堆相关的API可以用来创建, 分配, 释放和销毁堆空间.
- Windows 内核
Ntoskrnl.exe中, 还存在一份类似的堆管理器, 它负责 Windows 内核中的堆空间分配 (内核堆和用户的堆不是同一个).
10.3.4 堆分配算法
如何管理一大块连续的内存空间, 能够按照需求分配, 释放其中的空间, 这就是堆分配的算法.
- 空闲链表
- 空闲链表 (Free List) 的方法实际上就是把堆中各个空闲的块按照链表的方式连接起来, 当用户请求一块空间时, 可以遍历整个列表, 直到找到合适大小的块并且将它拆分. 当用户释放空间时将它合并到空闲链表中.
- 这样的空闲链表实现尽管简单, 但在释放空间的时候, 给定一个已分配块的指针, 堆无法确定这个块的大小. 一个简单的解决方法是当用户请求k个字节空间的时候, 我们实际分配 k+4 个字节, 这 4 个字节用于存储该分配的大小, 即 k+4.
- 一旦链表被破坏, 或者记录长度的那 4 字节被破坏, 整个堆就无法正常工作, 而这些数据恰恰很容易被越界读写所接触到.

- 位图
将整个堆划分为大量的块 (block) , 每个块的大小相同. 当用户请求内存的时候, 总是分配整数个块的空间给用户, 第一个块我们称为已分配区域的头 (Head) , 其余的称为已分配区域的主体 (Body). 而我们可以使用一个整数数组来记录块的使用情况, 由于每个块只有头/主体/空闲三种状态.
仅仅需要两位即可表示一个块, 因此称为位图.
示例

- 这个堆分配了 3 片内存, 分别有 2/4/1 个块, 用虚线框标出.
- 其对应的位图将是:
(HIGH) 11 00 00 10 10 10 11 00 00 00 00 00 00 00 10 11 (LOW) - 其中 11 表示 H (Head) , 10 表示主体 (Body) , 00表示空闲 (Free) .
几个优点
- 速度快: 由于整个堆的空闲信息存储在一个数组内, 因此访问该数组时 cache 容易命中.
- 稳定性好: 为了避免用户越界读写破坏数据, 我们只须简单地备份一下位图即可. 而且即使部分数据被破坏, 也不会导致整个堆无法工作.
- 块不需要额外信息, 易于管理.
缺点
- 分配内存的时候容易产生碎片. 例如分配 300 字节时, 实际分配了 3 个块即 384 个字节, 浪费了 84 个字节.
- 如果堆很大, 或者设定的一个块很小 (这样可以减少碎片) , 那么位图将会很大, 可能失去 cache 命中率高的优势, 而且也会浪费一定的空间. 针对这种情况, 我们可以使用多级的位图.
- 对象池
- 如果每一次分配的空间大小都一样, 那么就可以按照这个每次请求分配的大小作为一个单位, 把整个堆空间划分为大量的小块, 每次请求的时候只需要找到一个小块就可以了.
堆的分配算法往往是采取多种算法复合而成的.
- 比如对于 glibc 来说, 它对于小于 64 字节的空间申请是采用类似于对象池的方法. 而对于大于 512 字节的空间申请采用的是最佳适配算法. 对于大于 64 字节而小于 512 字节的, 它会根据情况采取上述方法中的最佳折中策略. 对于大于 128KB 的申请, 它会使用
mmap机制直接向操作系统申请空间.
- 比如对于 glibc 来说, 它对于小于 64 字节的空间申请是采用类似于对象池的方法. 而对于大于 512 字节的空间申请采用的是最佳适配算法. 对于大于 64 字节而小于 512 字节的, 它会根据情况采取上述方法中的最佳折中策略. 对于大于 128KB 的申请, 它会使用
第11章 运行库
11.1 入口函数和程序初始化
11.1.1 程序从 main 开始吗
首先运行的代码并不是 main 的第一行, 而是某些别的代码, 这些代码负责准备好 main 函数执行所需要的环境, 并且负责调用 main 函数, 这时候你才可以在 main 函数里放心大胆地写各种代码: 申请内存, 使用系统调用, 触发异常, 访问 I/O. 在 main 返回之后, 它会记录 main 函数的返回值, 调用 atexit 注册的函数, 然后结束进程.
入口函数或入口点 (Entry Point) . 程序的入口点实际上是一个程序的初始化和结束部分, 它往往是运行库的一部分.
- 操作系统在创建进程后, 把控制权交到了程序的入口, 这个入口往往是运行库中的某个入口函数.
- 入口函数对运行库和程序运行环境进行初始化, 包括堆, I/O, 线程, 全局变量构造, 等等.
- 入口函数在完成初始化之后, 调用 main 函数, 正式开始执行程序主体部分.
- main 函数执行完毕以后, 返回到入口函数, 入口函数进行清理工作, 包括全局变量析构, 堆销毁, 关闭 I/O等, 然后进行系统调用结束进程.
11.1.2 入口函数如何实现
glibc 的入口函数
只选取最简单的静态 glibc 用于可执行文件的时候作为例子.
Linux 下 glibc 的源代码, 在其中的子目录
libc/csu里.glibc 的程序入口为
_starti386 的
_start实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17libc\sysdeps\i386\elf\Start.S:
_start:
xorl %ebp, %ebp
popl %esi
movl %esp, %ecx
pushl %esp
pushl %edx
pushl $__libc_csu_fini
pushl $__libc_csu_init
pushl %ecx
pushl %esi
pushl main
call __libc_start_main
hlt在最开始的地方有3条指令
xor %ebp, %ebp: 这其实是让ebp寄存器清零. 这样做的目的表明当前是程序的最外层函数.pop %esi及mov %esp, %ecx: 在调用_start前, 装载器会把用户的参数和环境变量压入栈中, 按照其压栈的方法, 实际上栈顶的元素是argc, 而接着其下就是argv和环境变量的数组. 图11-1为此时的栈布局, 其中虚线箭头是执行pop %esi之前的栈顶 (%esp) , 而实线箭头是执行之后的栈顶 (% esp) .pop %esi将argc存入了esi, 而mov %esp, %ecx将栈顶地址 (此时就是argv和环境变量 (env) 数组的起始地址) 传给%ecx. 现在%esi指向argc,%ecx指向argv及环境变量数组.
开始的 7 个压栈指令用于给函数传递参数
最终调用了名为
__lib_start_main的函数可以把
_start改写为一段更具有可读性的伪代码:1
2
3
4
5
6
7
8void _start()
{
%ebp = 0;
int argc = pop from stack
char** argv = top of stack;
__libc_start_main( main, argc, argv, __libc_csu_init, __libc_csu_fini,
edx, top of stack );
}实际执行代码的函数是
__libc_start_main1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34_start -> __libc_start_main:
int __libc_start_main (
int (*main) (int, char **, char **),
int argc,
char * __unbounded *__unbounded ubp_av,
__typeof (main) init,
void (*fini) (void),
void (*rtld_fini) (void),
void * __unbounded stack_end)
{
char **argv;
int result;
char** ubp_ev = &ubp_av[argc + 1];
INIT_ARGV_and_ENVIRON;
__libc_stack_end = stack_end;
__pthread_initialize_minimal();
__cxa_atexit(rtld_fini, NULL, NULL);
__libc_init_first (argc, argv, __environ);
__cxa_atexit(fini, NULL, NULL);
(*init)(argc, argv, __environ);
result = main (argc, argv, __environ);
exit (result);
}__libc_start_main的函数头部, 可见和_start函数里的调用一致, 一共有 7 个参数.main 由第一个参数传入.
紧接着是
argc和argv(这里称为ubp_av, 因为其中还包含了环境变量表) .除了 main 的函数指针之外, 外部还要传入 3 个函数指针, 分别是:
init: main 调用前的初始化工作.fini: main 结束后的收尾工作.rtld_fini: 和动态加载有关的收尾工作,rtld是 runtime loader 的缩写.
最后的
stack_end标明了栈底的地址, 即最高的栈地址.
bounded pointer
- GCC 支持 bounded 类型指针 (bounded 指针用
__bounded关键字标出, 若默认为
bounded 指针, 则普通指针用__unbounded标出) , 这种指针占用 3 个指针的空间, 在第一个空间里存储原指针的值, 第二个空间里存储下限值, 第三个空间里存储上限值.__ptrvalue,__ptrlow,__ptrhigh分别返回这 3 个值, 有了 3 个值以后, 内存越界错误便很容易查出来了. 并且要定义__BOUNDED_POINTERS__这个宏才有作用, 否则这3个宏定义是空的. - 尽管 bounded 指针看上去似乎很有用, 但是这个功能却在 2003 年被去掉了. 因此现在所有关于 bounded 指针的关键字其实都是一个空的宏.
- GCC 支持 bounded 类型指针 (bounded 指针用
INIT_ARGV_and_ENVIRON这个宏定义于libc/sysdeps/generic/bp-start.h, 展开后本段代码变为:1
2
3
4
5
6char** ubp_ev = &ubp_av[argc + 1];
__environ = ubp_ev;
__libc_stack_end = stack_end;
char** ubp_ev = &ubp_av[argc + 1];
__environ = ubp_ev;
__libc_stack_end = stack_end;为什么要分两步赋值给
__environ呢?这又是为了兼容 bounded 惹的祸.
一连串的函数调用, 注意到
__cxa_atexit函数是 glibc 的内部函数, 等同于 atexit, 用于将参数指定的函数在 main 结束之后调用.在最后, main 函数终于被调用, 并退出.
exit 的实现:
1
2
3
4
5
6
7
8
9
10
11_start -> __libc_start_main -> exit:
void exit (int status)
{
while (__exit_funcs != NULL)
{
...
__exit_funcs = __exit_funcs->next;
}
...
_exit (status);
}其中
__exit_funcs是存储由__cxa_atexit和 atexit 注册的函数的链表.最后的
_exit函数由汇编实现, 且与平台相关, 下面列出 i386 的实现:1
2
3
4
5
6_start -> __libc_start_main -> exit -> _exit:
_exit:
movl 4(%esp), %ebx
movl $__NR_exit, %eax
int $0x80
hlt我们看到在
_start和_exit的末尾都有一个hlt指令, 这是作什么用的呢?- 一旦 exit 被调用, 程序的运行就会终止, 因此实际上
_exit末尾的hlt不会执行, 从而__libc_start_main永远不会返回, 以至_start末尾的hlt指令也不会执行._exit里的hlt指令是为了检测 exit 系统调用是否成功. 如果失败, 程序就不会终止,hlt指令就可以发挥作用强行把程序给停下来. 而_ start里的hlt的用处也是如此, 但是为了预防某种没有调用 exit (这里指的不是 exit 系统调用) 就回到_start的情况 (例如有人误删了__libc_main_start末尾的 exit) .
- 一旦 exit 被调用, 程序的运行就会终止, 因此实际上
MSVC CRT 入口函数
- (1) 初始化和 OS 版本有关的全局变量.
- (2) 初始化堆.
- (3) 初始化 I/O.
- (4) 获取命令行参数和环境变量.
- (5) 初始化 C 库的一些数据.
- (6) 调用 main 并记录返回值.
- (7) 检查错误并将 main 的返回值返回.

11.1.3 运行库与 I/O
一个程序的 I/O 指代了程序与外界的交互, 包括文件, 管道, 网络, 命令行, 信号等.
更广义地讲, I/O 指代任何操作系统理解为 “文件” 的事务.
设备, 磁盘文件, 命令行等–统称为文件, 因此这里所说的文件是一个广义的概念.
在操作系统层面上, 文件操作也有类似于
FILE的一个概念, 在 Linux 里, 这叫做文件描述符 (File Descriptor) , 而在 Windows 里, 叫做句柄 (Handle).- 用户通过某个函数打开文件以获得句柄, 此后用户操纵文件皆通过该句柄进行.
FILE,fd, 打开文件表和打开文件对象的关系如图
- 内核指针
p指向该进程的打开文件表, 所以只要有fd, 就可以用fd+p来得到打开文件表的某一项地址.stdin,stdout,stderr均是FILE结构的指针.
I/O 初始化的职责是什么
- 首先 I/O 初始化函数需要在用户空间中建立
stdin,stdout,stderr及其对应的FILE结构, 使得程序进入 main 之后可以直接使用printf,scanf等函数.
- 首先 I/O 初始化函数需要在用户空间中建立
11.1.4 MSVC CRT 的入口函数初始化
主要包含两个部分, 堆初始化和 I/O 初始化.
子主题 2
堆初始化
- MSVC的堆初始化过程出奇地简单, 它仅仅调用了HeapCreate这个API创建了一个系统堆.
- MSVC的malloc函数必然是调用了HeapAlloc这个API, 将堆管理的过程直接交给了操作系统.
I/O初始化
MSVC的I/O初始化主要进行了如下几个工作:
- 建立打开文件表.
- 如果能够继承自父进程, 那么从父进程获取继承的句柄.
- 初始化标准输入输出.
11.2 C/C++ 运行库
11.2.1 C 语言运行库
任何一个 C 程序, 它的背后都有一套庞大的代码来进行支撑, 以使得该程序能够正常运行. 这套代码至少包括入口函数, 及其所依赖的函数所构成的函数集合. 当然, 它还理应包括各种标准库函数的实现. 这样的一个代码集合称之为运行时库 (Runtime Library) .
C 语言的运行库, 即被称为 C 运行库 (CRT) .
一个 C 语言运行库大致包含了如下功能:
- 启动与退出: 包括入口函数及入口函数所依赖的其他函数等.
- 标准函数: 由 C 语言标准规定的 C 语言标准库所拥有的函数实现.
- I/O: I/O 功能的封装和实现, 参见上一节中 I/O 初始化部分.
- 堆: 堆的封装和实现, 参见上一节中堆初始化部分.
- 语言实现: 语言中一些特殊功能的实现.
- 调试: 实现调试功能的代码.
11.2.2 C 语言标准库
C 语言的标准库非常轻量, 它仅仅包含了数学函数, 字符/字符串处理, I/O 等基本方面.
- 标准输入输出 (
stdio.h) . - 文件操作 (
stdio.h) . - 字符操作 (
ctype.h) . - 字符串操作 (
string.h) . - 数学函数 (
math.h) . - 资源管理 (
stdlib.h) . - 格式转换 (
stdlib.h) . - 时间/日期 (
time.h) . - 断言 (
assert.h) . - 各种类型上的常数 (
limits.h & float.h) . - 变长参数 (
stdarg.h) . - 非局部跳转 (
setjmp.h) .
- 标准输入输出 (
变长参数
使用
- 函数内部定义类型为
va_list的变量:va_list ap;该变量以后将会依次指向各个可变参数. ap必须用宏va_start初始化一次, 其中lastarg必须是函数的最后一个具名的参数.va_start(ap, lastarg);.- 可以使用
va_arg宏来获得下一个不定参数 (假设已知其类型为type) :type next = va_arg(ap, type);. - 在函数结束前, 还必须用宏
va_end来清理现场.
- 函数内部定义类型为
变长参数的实现得益于 C 语言默认的 cdecl 调用惯例的自右向左压栈传递方式.
例子
设想如下的函数:
int sum(unsigned num, ...);其语义如下: 第一个参数传递一个整数num, 紧接着后面会传递num个整数, 返回num个整数的和.参数在栈上会形成如图11-7所示的布局.
sum函数的实现1
2
3
4
5
6
7
8int sum(unsigned num, ...)
{
int* p = &num + 1;
int ret = 0;
while (num--)
ret += *p++;
return ret;
}在这里我们可以观察到两个事实:
- (1)
sum函数获取参数的量仅取决于num参数的值, 因此, 如果num参数的值不等于实际传递的不定参数的数量, 那么sum函数可能取到错误的或不足的参数. - (2)
cdecl调用惯例保证了参数的正确清除. 我们知道有些调用惯例 (如stdcall) 是由被调用方负责清除堆栈的参数, 然而, 被调用方在这里其实根本不知道有多少参数被传递进来, 所以没有办法清除堆栈. 而cdecl恰好是调用方负责清除堆栈, 因此没有这个问题.
- (1)
va_list等宏应该如何实现va_list实际是一个指针, 用来指向各个不定参数. 由于类型不明, 因此这个va_list以void*或char*为最佳选择.va_start将va_list定义的指针指向函数的最后一个参数后面的位置, 这个位置就是第一个不定参数.va_arg获取当前不定参数的值, 并根据当前不定参数的大小将指针移向下一个参数.va_end将指针清 0.最简单的实现
1
2
3
4
变长参数宏
在 GCC 编译器下, 变长参数宏可以使用
##宏字符串连接操作实现, 比如:#define printf(args…) fprintf(stdout, ##args).在 MSVC 下, 我们可以使用
__VA_ARGS__这个编译器内置宏, 比如:#define printf(…) fprintf(stdout,__VA_ARGS__).
非局部跳转
- 使用非局部跳转, 可以实现从一个函数体内向另一个事先登记过的函数体内跳转, 而不用担心堆栈混乱.

11.2.3 glibc 与 MSVC CRT
C 语言的运行库从某种程度上来讲是 C 语言的程序和不同操作系统平台之间的抽象层, 它将不同的操作系统 API 抽象成相同的库函数.
虽然各个平台下的 C 语言运行库提供了很多功能, 但很多时候它们毕竟有限, 比如用户的权限控制, 操作系统线程创建等都不是属于标准的 C 语言运行库. 于是我们不得不通过其他的办法, 诸如绕过 C 语言运行库直接调用操作系统API或使用其他的库.
glibc 和 MSVCRT 事实上是标准 C 语言运行库的超集, 它们各自对 C 标准库进行了一些扩展.
- 像线程操作这样的功能并不是标准的 C 语言运行库的一部分, 但是 glibc 和 MSVCRT 都包含了线程操作的库函数.
glibc
GNU 操作系统的最初计划的内核是 Hurd, 一个微内核的构架系统. Hurd 因为种种原因开发进展缓慢, 而 Linux 因为它的实用性而逐渐风靡, 最后取代 Hurd 成了 GNU 操作系统的内核. 于是 glibc 从最初开始支持 Hurd 到后来渐渐发展成同时支持 Hurd 和 Linux, 而且随着 Linux 的越来越流行, glibc 也主要关注 Linux 下的开发, 成为了 Linux 平台的 C 标准库.
Linux 的开发者们因为开发的需要, 从 Linux 内核代码里面分离出了一部分代码, 形成了早期 Linux 下的 C 运行库. 这个 C 运行库又被称为 Linux libc. 这个版本的 C 运行库被维护了很多年, 从版本 2 一直开发到版本 5.
在此时 Linux libc 的开发者也认识到单独地维护一份 Linux 下专用的 C 运行库是没有必要的, 于是 Linux 开始采用 glibc 作为默认的 C 运行库, 并且将 2.x 版本的 glibc 看作是 Linux libc 的后继版本. 于是我们可以看到, glibc 在
/lib目录下的.so文件为libc.so.6, 即第六个 libc 版本, 而且在各个 Linux 发行版中, glibc 往往被称为 libc6.glibc 在 Linux 平台下占据了主导地位之后, 它又被移植到了其他操作系统和其他硬件平台, 诸如 FreeBSD, NetBSD 等, 而且它支持数十种 CPU 及嵌入式平台.
glibc 的发布版本主要由两部分组成
- 一部分是头文件, 比如
stdio.h, stdlib.h等, 它们往往位于/usr/include. - 另外一部分则是库的二进制文件部分. 二进制部分主要的就是 C 语言标准库, 它有静态和动态两个版本.
- 一部分是头文件, 比如
glibc 启动文件
- 由于当时有些链接器对链接时目标文件和库的顺序有依赖性,
crt.o这个文件必须被放在链接器命令行中的所有输入文件中的第一个, 为了强调这一点,crt.o被更名为crt0.o, 表示它是链接时输入的第一个文件. - 链接器在进行链接时, 会把所有输入目标文件中的
.init和.finit按照顺序收集起来, 然后将它们合并成输出文件中的.init和.finit. 但是这两个输出的段中所包含的指令还需要一些辅助的代码来帮助它们启动 (比如计算 GOT 之类的) , 于是引入了两个目标文件分别用来帮助实现初始化函数的crti.o和crtn.o. crt0.o也进行了升级, 变成了crt1.o. crt0.o和crt1.o之间的区别是crt0.o为原始的, 不支持.init和.finit的启动代码, 而crt1.o是改进过后, 支持.init和.finit的版本.
- 由于当时有些链接器对链接时目标文件和库的顺序有依赖性,
GCC 平台相关目标文件
crtbeginT.o及crtend.o, 这两个文件是真正用于实现 C++ 全局构造和析构的目标文件.libgcc.a里面包含的就是这种类似的函数, 这些函数主要包括整数运算, 浮点数运算 (不同的 CPU 对浮点数的运算方法很不相同) 等.libgcc_eh.a则包含了支持 C++ 的异常处理 (Exception Handling) 的平台相关函数.- 动态链接版本的
libgcc.a, 为libgcc_s.so.
MSVC CRT
同一个版本的 MSVC CRT 根据不同的属性提供了多种子版本, 以供不同需求的开发者使用.
按照静态/动态链接, 可以分为静态版和动态版. 按照单线程/多线程, 可以分为单线程版和多线程版. 按照调试/发布, 可分为调试版和发布版. 按照是否支持 C++ 分为纯 C 运行库版和支持 C++ 版. 按照是否支持托管代码分为支持本地代码/托管代码和纯托管代码版.
这些属性很多时候是相互正交的, 也就是说它们之间可以相互组合.
命名规则为:
libc [p] [mt] [d] .libp表示 C Plusplus, 即 C++ 标准库.mt表示 Multi-Thread, 即表示支持多线程.d表示 Debug, 即表示调试版本.
11.3 运行库与多线程
11.3.1 CRT 的多线程困扰
线程的访问权限
线程也拥有自己的私有存储空间, 包括:
- 栈 (尽管并非完全无法被其他线程访问, 但一般情况下仍然可以认为是私有的数据) .
- 线程局部存储 (Thread Local Storage, TLS) . 线程局部存储是某些操作系统为线程单独提供的私有空间, 但通常只具有很有限的尺寸.
- 寄存器 (包括PC寄存器) , 寄存器是执行流的基本数据, 因此为线程私有.

多线程运行库
这里我们所说的 “多线程相关” 主要有两个方面, 一方面是提供那些多线程操作的接口, 比如创建线程, 退出线程, 设置线程优先级等函数接口. 另外一方面是 C 运行库本身要能够在多线程的环境下正确运行.
- 对于第一方面, 主流的 CRT 都会有相应的功能.
- 对于第二个方面, C 语言运行库必须支持多线程的环境.
C/C++ 运行库在多线程环境下吃了不少苦头.
- (1)
errno: 在 C 标准库里, 大多数错误代码是在函数返回之前赋值在名为errno的全局变量里的. 多线程并发的时候, 有可能 A 线程的errno的值在获取之前就被B线程给覆盖掉, 从而获得错误的出错信息. - (2)
strtok()等函数都会使用函数内部的局部静态变量来存储字符串的位置, 不同的线程调用这个函数将会把它内部的局部静态变量弄混乱. - (3)
malloc/new与free/delete: 堆分配/释放函数或关键字在不加锁的情况下是线程不安全的. 由于这些函数或关键字的调用十分频繁, 因此在保证线程安全的时候显得十分繁琐. - (4) 异常处理: 在早期的 C++ 运行库里, 不同的线程抛出的异常会彼此冲突, 从而造成信息丢失的情况.
- (5)
printf/fprintf及其他 IO 函数: 流输出函数同样是线程不安全的, 因为它们共享了同一个控制台或文件输出. 不同的输出并发时, 信息会混杂在一起. - (6) 其他线程不安全函数: 包括与信号相关的一些函数.
- (1)
C 标准库中在不进行线程安全保护的情况下自然地具有线程安全的属性的函数.
- (1) 字符处理 (
ctype.h) , 包括isdigit,toupper等, 这些函数同时还是可重入的. - (2) 字符串处理函数 (
string.h) , 包括strlen,strcmp等, 但其中涉及对参数中的数组进行写入的函数 (如strcpy) 仅在参数中的数组各不相同时可以并发. - (3) 数学函数 (
math.h) , 包括sin, pow等, 这些函数同时还是可重入的. - (4) 字符串转整数/浮点数 (
stdlib.h) , 包括atof, atoi, atol, strtod, strtol, strtoul. - (5) 获取环境变量 (
stdlib.h) , 包括getenv, 这个函数同时还是可重入的. - (6) 变长数组辅助函数 (
stdarg.h) . - (7) 非局部跳转函数 (
setjmp.h) , 包括setjmp和longjmp, 前提是longjmp仅跳转到本线程设置的jmpbuf上.
- (1) 字符处理 (
11.3.2 CRT 改进
使用 TLS
errno必须成为各个线程的私有成员- 在 glibc 中,
errno被定义为一个宏, 如下:#define errno (*__errno_location ()).
- 在 glibc 中,
加锁
- 在多线程版本的运行库中, 线程不安全的函数内部都会自动地进行加锁.
改进函数调用方式
一种改进的办法就是修改所有的线程不安全的函数的参数列表, 改成某种线程安全的版本.
- 比如 MSVC 的 CRT 就提供了线程安全版本的
strtok()函数:strtok_s().1
2char *strtok(char *strToken, const char *strDelimit );
char *strtok_s( char *strToken, const char *strDelimit, char **context); - 改进后的
strtok_s增加了一个参数, 这个参数context是由调用者提供一个char*指针,strtok_s将每次调用后的字符串位置保存在这个指针中. 而之前版本的strtok函数会将这个位置保存在一个函数内部的静态局部变量中, 如果有多个线程同时调用这个函数, 有可能出现冲突.
- 比如 MSVC 的 CRT 就提供了线程安全版本的
11.3.3 线程局部存储实现
如果要定义一个全局变量为 TLS 类型的, 只需要在它定义前加上相应的关键字即可. 对于 GCC 来说, 这个关键字就是
__thread, 对于MSVC来说, 相应的关键字为__declspec(thread).Windows TLS 的实现
当我们使用
__declspec(thread)定义一个线程私有变量的时候, 编译器会把这些变量放到 PE 文件的.tls段中. 当系统启动一个新的线程时, 它会从进程的堆中分配一块足够大小的空间, 然后把.tls段中的内容复制到这块空间中, 于是每个线程都有自己独立的一个.tls副本.TLS 表 (
IMAGE_TLS_DIRECTORY结构) 中保存了所有 TLS 变量的构造函数和析构函数的地址, Windows 系统就是根据 TLS 表中的内容, 在每次线程启动或退出时对 TLS 变量进行构造和析构. TLS 表本身往往位于 PE 文件的.rdata段中.另外一个问题是, 既然同一个 TLS 变量对于每个线程来说它们的地址都不一样, 那么线程是如何访问这些变量的呢?
- 其实对于每个 Windows 线程来说, 系统都会建立一个关于线程信息的结构, 叫做线程环境块 (TEB, Thread Environment Block) . 这个结构里面保存的是线程的堆栈地址, 线程 ID 等相关信息, 其中有一个域是一个 TLS 数组, 它在 TEB 中的偏移是
0x2C.
- 其实对于每个 Windows 线程来说, 系统都会建立一个关于线程信息的结构, 叫做线程环境块 (TEB, Thread Environment Block) . 这个结构里面保存的是线程的堆栈地址, 线程 ID 等相关信息, 其中有一个域是一个 TLS 数组, 它在 TEB 中的偏移是
显式 TLS
隐式 TLS, 即程序员无须关心 TLS 变量的申请, 分配赋值和释放, 编译器, 运行库还有操作系统已经将这一切悄悄处理妥当了.
显式 TLS 的方法, 这种方法是程序员须要手工申请 TLS 变量, 并且每次访问该变量时都要调用相应的函数得到变量的地址, 并且在访问完成之后需要释放该变量.
- Windows 平台上, 系统提供了
TlsAlloc(), TlsGetValue(), TlsSetValue()和TlsFree()这 4 个 API 函数用于显式 TLS 变量的申请, 取值, 赋值和释放. - Linux 下相对应的库函数为
pthread库中的pthread_key_create(),pthread_getspecific(),pthread_setspecific()和pthread_key_delete().
- Windows 平台上, 系统提供了
TEB 结构中有个 TLS 数组. 实际上显式的 TLS 就是使用这个数组保存 TLS 数据的. 由于 TLS 数组的元素数量固定, 一般是 64 个, 于是显式 TLS 在实现时如果发现该数组已经被使用完了, 就会额外申请 4096 个字节作为二级 TLS 数组.
显式 TLS 的诸多缺点已经使得它越来越不受欢迎了, 我们并不推荐使用它.
11.4 C++ 全局构造与析构
11.4.1 glibc 全局构造与析构

链接器必须包装所有的
.dtor段的合并顺序必须是.ctor的严格反序, 这增加了链接器的工作量, 于是后来人们放弃了这种做法, 采用了一种新的做法, 就是通过__cxa_atexit()在exit()函数中注册进程退出回调函数来实现析构.由于全局对象的构建和析构都是由运行库完成的, 于是在程序或共享库中有全局对象时, 记得不能使用
- nonstartfiles或- nostdlib选项, 否则, 构建与析构函数将不能正常执行 (除非你很清楚自己的行为, 并且手工构造和析构全局对象) .Collect2- 实际上collect2是ld的一个包装
- 在有些系统上, 汇编器和链接器并不支持本节中所介绍的
.init.ctor这种机制, 于是为了实现在 main 函数前执行代码, 必须在链接时进行特殊的处理.Collect2这个程序就是用来实现这个功能的, 它会 “收集” (collect) 所有输入目标文件中那些命名特殊的符号, 这些特殊的符号表明它们是全局构造函数或在 main 前执行,collect2会生成一个临时的.c文件, 将这些符号的地址收集成一个数组, 然后放到这个.c文件里面, 编译后与其他目标文件一起被链接到最终的输出文件中. - 在这些平台上, GCC 编译器也会在 main 函数的开始部分产生一个
__main函数的调用, 这个函数实际上就是负责collect2收集来的那些函数.__main函数也是 GCC 所提供的目标文件的一部分, 如果我们使用-nostdlib编译程序, 可能得到__main函数未定义的错误, 这时候只要加上-lgcc把它链接上即可.
11.4.2 MSVC CRT 的全局构造和析构
11.5 fread 实现
11.5.1 缓冲
如果每次写数据都要进行一次系统调用, 让内核向屏幕写数据, 就明显过于低效了, 因为系统调用的开销是很大的, 它要进行上下文切换, 内核参数检查, 复制等, 如果频繁进行系统调用, 将会严重影响程序和系统的性能.
一个显而易见的可行方案是将对控制台连续的多次写入放在一个数组里, 等到数组被填满之后再一次性完成系统调用写入, 实际上这就是缓冲最基本的想法.
除了读文件有缓冲以外, 写文件也存在着同样的情况, 而且写文件比读文件要更加复杂, 因为当我们通过
fwrite向文件写入一段数据时, 此时这些数据不一定被真正地写入到文件中, 而是有可能还存在于文件的写缓冲里面, 那么此时如果系统崩溃或进程意外退出时, 有可能导致数据丢失, 于是 CRT 还提供了一系列与缓冲相关的操作用于弥补缓冲所带来的问题.C 语言标准库提供与缓冲相关的几个基本函数.

11.5.2 fread_s
fread将所有的工作都转交给了fread_ s.- 用户在使用
fread_s时就可以指定这个参数, 以达到防止越界的目的 (fread_s的 s 是 safe 的意思). fread_s首先对各个参数检查, 然后使用_lock_str对文件进行加锁, 以防止多个线程同时读取文件而导致缓冲区不一致. 我们可以看到fread_s其实又把工作交给了_fread_nolock_s.
11.5.3 fread_nolock_s


11.5.4 _read
主要负责两件事
- (1) 从文件中读取数据.
- (2) 对文本模式打开的文件, 转换回车符.
11.5.5 文本换行
回车 (换行) 的存储方式
Linux/Unix: 回车用
\n表示.Mac OS: 回车用
\r表示.Windows: 回车用
\r\n表示.- 回车 (换行) 的存储方式是
0x0D(用 CR 表示) ,0x0A(用 LF 表示) 这两个字节.
- 回车 (换行) 的存储方式是
11.5.6 fread 回顾
ReadFile调用轨迹

第12章 系统调用与 API
12.1 系统调用介绍
12.1.1 什么是系统调用
应用程序借助操作系统的原因
- 由于系统有限的资源有可能被多个不同的应用程序同时访问, 因此, 如果不加以保护, 那么各个应用程序难免产生冲突. 所以现代操作系统都将可能产生冲突的系统资源给保护起来, 阻止应用程序直接访问.
- 有一些行为, 应用程序不借助操作系统是无法办到或不能有效地办到的.
每个操作系统都会提供一套接口, 以供应用程序使用. 这些接口往往通过中断来实现.
- Linux 使用
0x80号中断作为系统调用的入口. - Windows 采用
0x2E号中断作为系统调用入口.
- Linux 使用
系统调用的要求
首先系统调用必须有明确的定义, 即每个调用的含义, 参数, 行为都需要有严格而清晰的定义, 这样应用程序 (运行库) 才可以正确地使用它.
其次它必须保持稳定和向后兼容.
- 所以操作系统的系统调用往往从一开始定义后就基本不做改变, 而仅仅是增加新的调用接口, 以保持向后兼容.
对于 Windows 来讲, 系统调用实际上不是它与应用程序的最终接口, 而是 API.
12.1.2 Linux 系统调用
在 x86 下, 系统调用由
0x80中断完成, 各个通用寄存器用于传递参数,EAX寄存器用于表示系统调用的接口号.每个系统调用都对应于内核源代码中的一个函数, 它们都是以
sys_开头的.当系统调用返回时,
EAX又作为调用结果的返回值.常见的系统调用

12.1.3 系统调用的弊端
大部分操作系统的系统调用都有两个特点:
- 使用不便. 操作系统提供的系统调用接口往往过于原始, 程序员须要了解很多与操作系统相关的细节. 如果没有进行很好的包装, 使用起来不方便.
- 各个操作系统之间系统调用不兼容. 即使是同系列的操作系统的系统调用都不一样, 比如 Linux 和 UNIX 就不相同.
“解决计算机的问题可以通过增加层来实现” , 于是运行库挺身而出, 它作为系统调用与程序之间的一个抽象层可以保持着这样的特点:
- 使用简便. 因为运行库本身就是语言级别的, 它一般都设计相对比较友好.
- 形式统一. 运行库有它的标准, 叫做标准库, 凡是所有遵循这个标准的运行库理论上都是相互兼容的, 不会随着操作系统或编译器的变化而变化.
运行时库将不同的操作系统的系统调用包装为统一固定的接口, 使得同样的代码, 在不同的操作系统下都可以直接编译, 并产生一致的效果. 这就是源代码级上的可移植性.
12.2 系统调用原理
12.2.1 特权级与中断
一般来说, 运行在高特权级的代码将自己降至低特权级是允许的, 但反过来低特权级的代码将自己提升至高特权级则不是轻易就能进行的, 否则特权级的作用就有名无实了.
在将低特权级的环境转为高特权级时, 须要使用一种较为受控和安全的形式, 以防止低特权模式的代码破坏高特权模式代码的执行.
操作系统一般是通过中断 (Interrupt) 来从用户态切换到内核态.
中断一般具有两个属性
- 一个称为中断号 (从 0 开始)
- 一个称为中断处理程序 (Interrupt Service Routine, ISR) .
中断过程
- 不同的中断具有不同的中断号, 而同时一个中断处理程序一一对应一个中断号. 在内核中, 有一个数组称为中断向量表 (Interrupt Vector Table) , 这个数组的第 n 项包含了指向第 n 号中断的中断处理程序的指针. 当中断到来时, CPU 会暂停当前执行的代码, 根据中断的中断号, 在中断向量表中找到对应的中断处理程序, 并调用它. 中断处理程序执行完成之后, CPU 会继续执行之前的代码.

中断有两种类型
- 硬件中断
- 软件中断
和中断一样, 系统调用都有一个系统调用号, 就像身份标识一样来表明是哪一个系统调用, 这个系统调用号通常就是系统调用在系统调用表中的位置.
12.2.2 基于 int指令 的 Linux 的经典系统调用实现

- 触发中断
_syscall0例子:
fork函数是一个对系统调用fork的封装, 可以用下列宏来定义它:_syscall0(pid_t, fork);.i386 版本的
syscall0定义:1
2
3
4
5
6
7
8
9
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \
__syscall_return(type,__res); \
}__asm__是一个 gcc 的关键字, 表示接下来要嵌入汇编代码.volatile关键字告诉 GCC 对这段代码不进行任何优化.__asm__的第一个参数是一个字符串, 代表汇编代码的文本. 这里的汇编代码只有一句:int $0x80, 这就要调用0x80号中断."=a" (__res)表示用eax(a 表示eax) 输出返回数据并存储在__res里."0 " (__NR_##name))表示__NR_##name为输入,"0"指示由编译器选择和输出相同的寄存器 (即eax) 来传递参数.__NR_fork是一个宏, 表示fork系统调用的调用号.对于 x86 体系结构, 该宏的定义可以在
Linux/include/asm-x86/unistd_32.h里找到:1
2
3
4
5
6
......_syscall_return是另一个宏1
2
3
4
5
6
7
8
do { \
if ((unsigned long)(res) >= (unsigned long)(-125)) { \
errno = -(res); \
res = -1; \
} \
return (type) (res); \
} while (0)- 用于检查系统调用的返回值, 并把它相应地转换为 C 语言的
errno错误码. - 在 Linux 里, 系统调用使用返回值传递错误码, 如果返回值为负数, 那么表明调用失败, 返回值的绝对值就是错误码. 而在 C 语言里则不然, C 语言里的大多数函数都以返回 -1 表示调用失败, 而将出错信息存储在一个名为
errno的全局变量 (在多线程库中,errno存储于 TLS 中) 里.
- 用于检查系统调用的返回值, 并把它相应地转换为 C 语言的
第一个参数为这个系统调用的返回值类型.
第二个参数是系统调用的名称 .
把这段汇编改写为更为可读的格式:
1
2
3
4
5
6
7
8
9
10main -> fork:
pid_t fork(void)
{
long __res;
$eax = __NR_fork
int $0x80
__res = $eax
__syscall_return(pid_t,__res);
}
_syscall11
2
3
4
5
6
7
8
9
type name(type1 arg1) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name), "b" ((long)(arg1))); \
__syscall_return(type,__res); \
}多了一个
"b" ((long)(arg1)). 这一句的意思是先把arg1强制转换为long, 然后存放在EBX(b 代表EBX) 里作为输入. 编译器还会生成相应的代码来保护原来的EBX的值不被破坏.汇编可以改写为
1
2
3
4
5
6push ebx
eax = __NR_##name
ebx = arg1
int 0x80
__res = eax
pop ebx
x86 下 Linux 支持的系统调用参数至多有 6 个, 分别使用 6 个寄存器来传递, 它们分别是
EBX, ECX, EDX, ESI, EDI和EBP.glibc 使用了另外一套调用系统调用的方法, 尽管原理上仍然是使用
0x80号中断, 但细节上却是不一样的.
- 切换堆栈
将当前栈由用户栈切换为内核栈的实际行为就是
- (1) 保存当前的
ESP,SS的值. - (2) 将
ESP,SS的值设置为内核栈的相应值.
- (1) 保存当前的
反过来, 将当前栈由内核栈切换为用户栈的实际行为则是:
- (1) 恢复原来
ESP,SS的值. - (2) 用户态的
ESP和SS的值保存在哪里呢?答案是内核栈上. 这一行为由 i386 的中断指令自动地由硬件完成.
- (1) 恢复原来
当
0x80号中断发生的时候, CPU 除了切入内核态之外, 还会自动完成下列几件事:(1) 找到当前进程的内核栈 (每一个进程都有自己的内核栈) .
(2) 在内核栈中依次压入用户态的寄存器
SS, ESP, EFLAGS, CS, EIP.- 而当内核从系统调用中返回的时候, 须要调用iret指令来回到用户态, iret指令则会从内核栈里弹出寄存器SS, ESP, EFLAGS, CS, EIP的值, 使得栈恢复到用户态的状态.

- 中断处理程序
- Linux i386 中断服务流程:

- Linux 系统调用流程:

- Linux 系统调用中如何向内核传递参数:

12.2.3 Linux 的新型系统调用机制
由于基于
int指令的系统调用在奔腾 4 代处理器上性能不佳, Linux 在 2.5 版本起开始支持一种新型的系统调用机制. 这种新机制使用 Intel 在奔腾 2 代处理器就开始支持的一组专门针对系统调用的指令–sysenter和sysexit.引入
ldd来获取一个可执行文件的共享库的依赖情况:1
2$ ldd /bin/ls
linux-gate.so.1 => (0xffffe000)linux-gate.so.1没有与任何实际的文件相对应.
展开
Linux 用于支持新型系统调用的 “虚拟” 共享库.
linux-gate.so.1并不存在实际的文件, 它只是操作系统生成的一个虚拟动态共享库 (Virtual Dynamic Shared Library, VDSO) . 这个库总是被加载在地址0xffffe000的位置上.用如下方法将它导出到一个真实的文件里:
$dd if=/proc/self/mem of=linux-gate.dso bs=4096 skip=1048574 count=1.vdso导出了一系列函数, 当然这里最值得关心的是__kernel_vsyscall函数. 这个函数负责进行新型的系统调用.- 调用汇编指令
sysenter.
- 调用汇编指令
自己调用
__kernel_vsyscall函数1
2
3
4
5
6
7
8
9
10
11
12
13int main() {
int ret;
char msg[] = "Hello\n";
__asm__ volatile (
"call *%%esi"
: "=a" (ret)
: "a" (4),
"S" (0xffffe400),
"b" ((long) 1),
"c" ((long) msg),
"d" ((long) sizeof(msg)));
return 0;
}- 在 Linux 下
fd=1表示stdout. 因此向fd=1写入数据等效于向命令行输出. - 我们在 main 函数里将
__kernel_vsyscall函数的地址赋值给esi(S 表示esi), 并且使用指令call调用这个地址. 与此同时, 还在eax中放入了系统调用write的调用号(4), 在ebx,ecx,edx中放入write的参数, 这样就完成了一次系统调用, 在屏幕上输出了 Hello.
- 在 Linux 下
12.3 Windows API
略过
第13章 运行库实现
比较适合修改源码运行找感觉, 因此略过.
《程序员的自我修养--链接装载与库》学习笔记 Part 4 库与运行库
https://www.chuxin911.com/linkage_loading_lib_part4_lib_runtime_lib_20220625/